
Source: "Piled Higher and Deeper" by Jorge Cham, www.phdcomics.com
Concluyo con esta entrada mi serie sobre cómo aprender métodos cuantitativos en economía (las primeras cuatro entradas se encuentran aquí, aquí, aquí y aquí).
En la entrega anterior me centré en los lenguajes de programación que resultaban, en mi opinión, más útiles para un estudiante o investigador en economía. Mencioné en varias ocasiones, sin embargo, que alrededor del uso de un lenguaje existía una nube de herramientas que uno tenía que manejar con cierta familiaridad y que dejaba para un análisis en mayor detalle. Este cometido es lo que pretendo hoy de manera muy sucinta y a riesgo, por restricciones de espacio, de dejarme muchas cosas en el tintero (como algunas de estas herramientas) y con todas las advertencias, además, sobre la subjetividad de muchos de mis comentarios que es pertinente repetir aquí. El lector interesado puede encontrar muchas de estas herramientas descritas también en A Gentle Introduction to Effective Computing in Quantitative Research: What Every Research Assistant Should Know de Harry J. Paarsch y Konstantin Golyaev.

Sistema operativo
Antes de entrar en la parte principal de la entrada he de resaltar que yo trabajo en Mac o en Linux, pero nunca en Windows. Mac o Linux le permiten a uno, con un botón, abrir una terminal de la familia Unix (Mac es Unix puro, Linux un hermano) y tener a su alcance un sistema operativo robusto como ninguno y en el que programar un código propio no va a ser una aventura. Cada año que doy clase de métodos computacionales en economía veo a cantidad de estudiantes terminar tirando en frustración su ordenador Windows por la ventana y cambiarse a Linux (los Macs salen caros para ellos). Mientras que con un poco de paciencia uno puede normalmente conseguir que todo corra en Windows, no le he visto nunca la mínima ventaja a emplear un sistema operativo que solo da dolores de cabeza. Además aprender Unix o Linux es muy fácil: en un par de horas uno está familiarizado con las instrucciones básicas y un poco de búsqueda en Internet le dará respuesta a casi todas las preguntas adicionales que aparezcan. Una vez que uno sabe Unix, conoce un sistema operativo para siempre: no va a cambiar en la siguiente versión creada por una empresa informática para ganar dinero. Un programador que supiese Unix en 1980 podría emplear hoy mi Mac sin mayor secreto.

Un sitio excelente para aprender Unix (y, en general, todos los temas que discuto en esta entrada) es software-carpentry, una fundación sin ánimo de lucro que organiza talleres y publica lecciones en la red sobre manejo de ordenadores para investigadores (con una hermana, Data Carpentry, más centrada en enseñar análisis de datos). Por ejemplo, está lección sobre el shell de Unix le permite a uno arrancar sin problema.

Para aprender más, en clase recomiendo Learning Unix for OS X: Going Deep With the Terminal and Shell (2nd ed.) de Dave Taylor, que es el que yo tengo siempre a mano y Linux Pocket Guide: Essential Commands (3rd ed.) de Daniel J. Barrett. Pero existen, eso sí, decenas de otros libros tan solventes como los que recomiendo y, además, textos más avanzados sobre Unix. Pero no creo que estos sean necesarios para la gran mayoría de los economistas. Yo tengo en la oficina Unix in a Nutshell (4th ed.) de Arnold Robbins por si acaso, pero la verdad es que no lo abro nunca.
Independientemente de si el argumento anterior en favor de Mac/Linux es convincente, sí que el lector deberá de tener en la cabeza mi estructura de trabajo cuando juzgue el resto de mis recomendaciones: toda mi experiencia es sobre el funcionamiento de las herramientas de las que hablaré en Mac o en Linux. No puedo decir mucho sobre lo bien que funcionan en Windows.
Editores
Si uno va a escribir código, necesita o bien un editor o un entorno de desarrollo integrado. Ambas rutas tienen ventajas y desventajas, pero en todo caso tener a mano un buen editor es siempre útil (aunque solo sea para abrir y modificar ficheros de texto eficazmente).
La semana pasada mencionaba alguno de los editores clásicos como GNU Emacs o Vim, que están acompañados de otras alternativas como Ultraedit y Notepad++. Mientras que los mismos siguen siendo herramientas excelentes y que se actualizan con nuevas versiones, mucha gente ha adoptado editores de nueva generación. Entre ellos destacan Atom, Sublime y Visual Studio Code.

Yo, en mi trabajo diario, empleo Atom, tanto para escribir en Latex como para escribir en C++ o en Julia (para R empleo RStudio y para Matlab el IDE de Mathworks, volveré a ellos en un momento).
Atom es un editor con un diseño moderno, de código abierto, que permite desde un uso muy sencillo a una adaptación a las necesidades de cada usuario muy sofisticada. Por ejemplo, es muy fácil cambiar el esquema de colores o la manera en que los archivos aparecen y uno puede compilar Latex, escribir un código en su lenguaje favorito, interactuar con Git y mantener una lista de tareas para el día sin abandonar la misma ventana y a una distancia de un golpe de pestaña. El número de paquetes es muy amplio y permite una instalación básica del editor muy ligera.
Sublime es muy similar a Atom en su concepción excepto que cuesta $70. A menos que uno tenga un motivo poderoso para emplear Sublime, es razón más que suficiente para no emplearlo; no tanto por los $70 sino por la limitación que los mismos supondrán al crecimiento de la comunidad de usuarios en el medio plazo.
La tercera posibilidad es Visual Studio Code. Aunque es un producto de Microsoft, ha sido lanzado en código abierto. Yo no lo he empleado nunca.
El lector interesado puede encontrar comparativas de estos tres editores más Vim aquí. Una lista exhaustiva de editores con puntuaciones de un grupo de evaluadores, aquí.
Entornos de desarrollo integrado
Muchos programadores prefieren emplear un entorno de desarrollo integrado, que agrupa un editor sofisticado para escribir código, un compilador, un depurador, control de código, un listado de comentarios (incluidos TODOs y otros), etc. La principal ventaja de los mismos es tener todo al alcance de un golpe de ratón o de un comando y poder implementar programación visual de una manera directa. La desventaja es que algunas veces los entornos le abruman a uno: son como esos coches modernos en los que te sientas y no sabes donde mirar de todos las indicadores que tienen.

Los dos entornos más populares son Eclipse y Visual Studio. Yo, en el pasado, cuando escribía en C++, Fortran o Scala, he empleado Eclipse. Visual Studio lo utilicé hace muchos años en una versión anterior.
Eclipse, que es de código abierto, lo tiene absolutamente todo, desde la última herramienta de programación en paralelo a una flexibilidad absoluta en configuración. Siguiendo mi analogía, es como un Mercedes S600 con todas las opciones: mires lo que mires, ahí esta. Y como un Mercedes, la ingeniería del mismo es extraordinaria. A la vez, algunas veces uno se pregunta para qué sirven esos 920 botones que no ha empleado nunca (exagero, pero solo un pelín  )
)

Más ligeros en sus contenidos y quizás más fáciles de emplear para un economista son Netbeans y Xcode (que integra muy bien con los Mac). Uno de mis coautores lo hace todo en Netbeans y está muy contento con él. Xcode me imagino que es una buena opción si quieres escribir apps para el Iphone. Yo lo he empleado un par de veces y, al final, he terminado cerrándolo y abriendo Eclipse. Ya puestos a sacar el coche, sacas el Mercedes.
Existen además los entornos diseñados específicamente para cada lenguaje. RStudio, para R, es francamente bueno: muy facil de emplear, con todo lo que uno necesita a mano, etc. Matlab tiene su propio editor y, dado que habla con la pantalla de ejecución de manera rápida y la configuración ya te viene dada, normalmente no merece la pena emplear otro editor distinto.

Finalmente querría resaltar Jupyter, una aplicación para la red en código abierto para crear y compartir documentos con código en diferentes lenguajes, datos, ecuaciones, etc. Yo la he empleado un par de veces pero dada la popularidad que esta ganando recientemente probablemente le dedique algo de tiempo a aprender Jupyter mejor durante mis clases en otoño.
Librerías
Una idea que ha surgido varias veces en los comentarios de entradas anteriores es que muchas de las cosas que uno necesita implementar vienen ya en librerías (o paquetes, como se llaman en algunos contextos). Mi respuesta fue que, efectivamente, uno podía muy a menudo pero no siempre, emplear estas librerías (y, además, hay que ser un usuario inteligente de las mismas). Es el momento aquí de revisitar este tema.
Dos librerías muy comunes en métodos numéricos son Armadillo y Eigen (ambas herederas a distancia de BLAS y LAPACK). Armadillo, para C++ y todos los lenguajes que interactúan bien con C++ como Julia o R, es la más sencilla de emplear de las dos y tiene todas las funciones necesarias de álgebra lineal con un sintaxis deliberadamente similar a la de Matlab para conseguir una facilidad de uso de las matrices. Eigen es más poderosa pero también algo más compleja de aprender.
Otras librerías a resaltar son la GNU Scientific Library y GMP para aritmética de alta precisión (por ejemplo, en problemas de estimación, doble precisión da algunas veces problemillas).
Numerical Recipes, de la que ya hablé, es otra librería muy conocida, aunque algunas veces un poco pedestre. Matlab, Julia, R y Python tienen muchas librerías/paquetes que me resulta imposible repasar ahora. Una búsqueda en internet o algunos libros como este le dará al lector toda la información que requiera.
Control de versiones
En cuanto uno empieza a programar o, simplemente, escribir un trabajo de investigación un poco serio se encuentra con la aparición de múltiples versiones del mismo fichero. Una solución sencilla (y que solventa de vez en cuando los problemas) es ser cuidadoso y tener diferentes versiones de cada fichero identificadas con la fecha de edición o similares. Pero si esta estrategia de pobre le saca a uno de un apuro, no es escalable y cruje en cuanto tiene más de un par de coautores que van por libre. Más de una vez el insistir en el control de versiones me ha sacado de algún apuro serio y por ello lo recomiendo enfáticamente.

La solución profesional es emplear un software de control de versiones. El más popular hoy en día (y creo el más extendido entre los economistas) es Git. Existe también una variante en la red, Github, que se ha convertido en uno de los medios de difundir código más común.

De nuevo, existen decenas de libros sobre Git, pero el que yo recomiendo es Version Control with Git: Powerful tools and techniques for collaborative software development (2nd ed.) de Jon Loeliger y Matthew McCullough. Las ideas básicas de Git se aprenden en un par de horas.
Aunque no exactamente control de versión, es también útil tener una herramienta para actualizar todos los programas instalados en el ordenador. Yo empleo Macports: es superfacil.
Compiladores

Cuando mencionaba, en mi entrada anterior, lenguajes de programación como C++ o Fortran pase de puntillas sobre la idea del compilador que uno necesita para generar un código ejecutable (si uno quiere aprender de verdad que es un compilador, el “el libro del dragón” sigue siendo la referencia clave).

La elección clara para un economista es GCC, la colección de compiladores de GNU. Gracias a ella uno tiene compiladores para todos los lenguajes comunes de la máxima calidad, técnicamente actualizados, de código abierto y que generar código muy rápido (sí, el mismo código compilado con dos compiladores diferentes puede correr a velocidades muy diversas, con diferencias a veces de mas de 100% incluso con las mismas banderas de compilación, por ejemplo una comparativa de compiladores de Fortran aquí). Además, enlazar GCC con Atom o Eclipse es cosa de cinco minutos.
Hoy existe una alternativa: la infraestructura de compiladores LLVM, que es la que está, por ejemplo, detrás del JIT de Julia. Los compiladores de LLVM enfatizan aspectos como tamaño del ejecutable y reducción en la velocidad de compilación que son importantes en la industria pero quizás algo menos en economía. Mi experiencia es que LLVM genera ejecutables un 10% más lentos que GCC, pero tales mediciones dependen, claro, tanto de los problemas que he corrido como de mi estilo de programación. Aquí, aquí y aquí hay comparativas en detalle.
Finalmente están los compiladores de Intel, relativamente populares entre los economistas porque el compilador de Fortran es el heredero directo del venerable Digital Visual/Compaq Fortran. Pero hoy en día, con GCC y LLVM en el mercado y la posibilidad de integrarlos en Atom o Eclipse, no veo razones poderosas para pagar lo que cuestan estos compiladores de Intel (y, de nuevo en mi experiencia, el ejecutable generado por GCC es ligeramente más rápido que el generado por Intel).
Antes de pasar a la siguiente materia una sugerencia: invertir un poco de tiempo en aprender a manejar bien un compilador (las distintas banderas, etc.) es enormemente rentable en términos de velocidad, eficiencia, etc. La documentación en las páginas de cada compilador es normalmente el mejor lugar para ello.
Programa para controlar la recompilación
En cuanto uno se pone a compilar, desde un programa sencillito o un fichero de LaTex, pronto se da cuenta que es tremendamente aburrido tener que teclear todos los comandos y opciones y, que además, la mitad de las veces cometes un error. Para eso están los ficheros de control de recompilación, los famosos makefiles, que te permiten recompilar de manera rápida, compilar distintas versiones de un fichero (esto es increíblemente util para mí cuando escribo mis manuscritos largos), limpiar ficheros antiguos, etc.
Mi primer trabajo como ayudante de investigación en Minnesota fue escribir makefiles uno detrás de otro. En su día me pareció aburrido hasta que aprendí que quien programó la versión original de make, Stuart Feldman, lo creo en su labor de becario un verano. Estas curas de humildad son las que le ponen a uno en su sitio en la jerarquía intelectual y le impiden quejarse.

Hay muchos programas para generar makefiles. Yo soy un clasicón con este tema y siempre empleo GNU Make, que además ya viene instalado en casi todas las distribuciones de Unix. Una referencia completa es Managing Projects with GNU Make: The Power of GNU Make for Building Anything (3rd ed.) de Robert Mecklenburg. Además uno se puede bajar un par de makefiles de internet y emplearlos como plantillas para empezar a entender cómo emplearlos.
Depuradores
“1. That can’t happen.
2. That doesn’t happen on my machine.
3. That shouldn’t happen.
4. Why does that happen?
5. Oh, I see.
6. How did that ever work?”
Six Stages of Debugging
Si el lector ha llegado hasta aquí, ya le puedo contar la verdad: la primera vez que escriba el código no va a correr. Y probablemente ni la segunda ni la tercera. Y cuando ya corra, le saldrá que el tipo de interés del modelo es 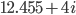 por ciento al mes, lo cual no tiene mucho sentido, aunque solo sea por el componente imaginario. Obviamente el programa tiene errores (“bugs”, como el que le salta a Cecilia en la tira cómica que abre esta entrada).
por ciento al mes, lo cual no tiene mucho sentido, aunque solo sea por el componente imaginario. Obviamente el programa tiene errores (“bugs”, como el que le salta a Cecilia en la tira cómica que abre esta entrada).
Uno se puede poner a buscar los errores a lo bruto corriendo el código linea a linea hasta encontrarlos. O uno puede emplear un depurador y seguir las técnicas desarrolladas por décadas para encontrar los errores de manera sistemática. Una introducción general al tema, con muchos ejemplos reales, es Why Programs Fail, Second Edition: A Guide to Systematic Debugging (2nd ed.) de Andreas Zeller.

Hay muchísimos depuradores. Como yo empleo los compiladores GCC, lo que es más conveniente para mi es emplear el depurador asociado, GDB. Una buena introducción al mismo es The Art of Debugging with GDB and DDD de Norman Matloff y Peter Jay Salzman.
RStudio y Matlab tienen sus depuradores propios (siempre me sorprende la cantidad de estudiantes e incluso investigadores que no conocen estas herramientas en entornos que emplean a diario).
Relacionados con los depuradores tenemos las herramientas de linting y pruebas unitarias. Linting sirve para detectar código sospechoso de manera estática (es decir, antes de compilarlo y/o correrlo) y obligar a seguir un estilo (más detalles sobre estilo en unos párrafos). Muchos lectores ya habrán usado una herramienta de linting sin percatarse: son esas cajitas de colores que salen en la columna de la derecha del editor de Matlab (aquí más detalles). Otras herramientas de linting incluyen Lint y Splint. Las pruebas unitarias buscan asegurarnos que un módulo del código funciona como se supone que tiene que hacerlo. Matlab tiene una suite de pruebas unitarias que están muy bien explicadas. Puede ser un primer lugar para familiarizarse con esta técnica.
Análisis de rendimiento
“Premature optimization is the root of all evil.”
Donald Knuth
Vale, ya el programa corre y nos da un resultado sensato. El problema es que tarda 3 horas. Si uno solo tuviese que correr el código una vez, esto no supondría excesivo obstáculo: un poco de paciencia y ya se soluciona. Desafortunadamente, en realidad uno tiene que correr el código muchísimas veces: para mirar que ocurre cuando cambia valores de parámetros, para anidarlo en una estimación estructural, etc. Y, a menudo, no son ni 3 horas, son 30 o 300.
La solución es optimizar el código para ver si podemos lograr que corra más deprisa. Aunque esto no siempre es posible, muchas veces hay fallos en el diseño del código que ralentizan su ejecución (aunque el resultado final sea el correcto). Estos fallos, además, pueden ser muy sutiles. En clase, por ejemplo, siempre le pido a los estudiantes que corran el siguiente código en Matlab (escrito por claridad, no por elegancia):
% Example of locality in memory allocation
m = 2000; % Try 1000, 2000, 5000
n = 10000;
% A smart way to do it
tic
a = zeros(m,n);
toc
clear a
% A not so smart way to do it
% a = zeros(m,n); % Comment in to check latency even with preallocation
tic
for j = 1:n
for i = 1:m
a(i,j) = 0.d0;
end
end
toc
clear a
% A really dumb way to do it
% a = zeros(m,n); % Comment in to check latency even with preallocation
tic
for i = 1:m
for j = 1:n
a(i,j) = 0.d0;
end
end
toc
El objetivo es llenar una matriz de información (por ejemplo, que hemos leído de datos). Primero, hago todas las entradas cero de una manera eficiente y mido la velocidad de ejecución. Luego, hago lo mismo pero con dos bucles anidados, con el bucle interior iterando sobre filas. Esta segunda alternativa es lo que tendríamos que hacer si cada entrada es diferente y viene de otra parte del código o de un fichero externo (algunas veces se puede cargar la matriz entera de una vez, pero imaginemos que no se puede en el problema concreto al que nos enfrentamos). Finalmente, repito el ejercicio pero iterando sobre columnas en el bucle interior. Esta última manera de implementar el código es mucho más lenta que la segunda. Si tiene, querido lector, un Matlab a mano, corra usted el código y compruébelo por si mismo.
¿Cuál es el motivo de esta más que considerable diferencia en velocidad cuando los dos códigos hacen lo mismo? La manera en la que Matlab guarda la información en memoria y como accede a ella. Las matrices pueden ser guardadas en un orden de dominancia de fila o columna (row- and column-major order). Matlab implementa una dominancia de columna y por eso el tercer ejemplo nos da tan malos resultados. Dedicarle 5 minutos a averiguar cómo le gusta a nuestro lenguaje guardar matrices en memoria es una de las mejores inversiones que un programador en economía puede hacer.
Más en detalle, uno puede aprender a emplear una herramienta de análisis de rendimiento como el profiler de Matlab, el de R o el de los compiladores GCC. Hace unos años había una institución famosa en economía (no quiero decir el nombre) que tenía que correr un programa que les demoraba en exceso y estaban pensando en paralelizarlo todo (con el consiguiente coste en horas y dinero). Desafortunadamente no tenían a nadie en plantilla que supiese de estas cosas (su informático sabía de redes y wifi, que es para lo que le pagan y de lo que yo lo desconozco casi todo) y, aprovechando que yo pasaba por ahí, el director me pidió que le diese un vistazo al código. Con el profiler de Matlab encontré el problema en 5 minutos, un “hot spot” un poco tonto que habían creado y que no tenía mayor secreto en re-escribirse con un par de lineas. No cuento esta anécdota para presumir, pues no fue mérito mío. Todo el mérito fue emplear una herramienta adecuada para el problema. El fallo de la institución no fue crear un “hot spot” innecesario. El fallo fue no emplear una herramienta para eliminarlo.

Matlab tiene unas páginas muy útiles sobre este tema y la mayoría de las lecciones en las mismas sirven para casi todos los lenguajes. Varios de los libros que recomendé la semana pasada también incluyen secciones sobre este tema. En Julia tenemos Julia High Performance de Avik Sengupta.

Más globales son Introduction to High-Performance Scientific Computing, de Victor Eijkhout, que tiene la ventaja de estar colgado gratis en Internet, e Introduction to High Performance Computing for Scientists and Engineers de Georg Hager (cuya página tiene mucho material adicional de gran utilidad) y Gerhard Wellein (una segunda edición está a punto de salir).
Programación en paralelo
Las referencias anteriores me obligan a tratar, de manera muy rápida, la programación en paralelo. Hoy en día la problemas de más alta dimensionalidad se implementan no en ordenadores con procesadores muy potentes, sino en ordenadores con muchos procesadores. Incluso la mayoría de los teléfonos móviles actuales vienen de fábrica con varios procesadores.
Dada la longitud de esta entrada y que programar en paralelo es algo un poco más avanzado, voy solo a dar dos pinceladas. En el futuro quizás vuelva a este tema (mi propio papel sobre el tema aquí).

Para las técnicas clásicas de OpenMP y MPI, uno tiene An Introduction to Parallel Programming de Peter Pacheco más las dos páginas que he enlazado, que incluyen muchos tutoriales. Para las técnicas más avanzadas de paralelización masiva, sobre todo en GPUs, Programming Massively Parallel Processors: A Hands-on Approach (3rd ed.) de David B. Kirk (que es alguien que de verdad sabe de esto) y Wen-mei W. Hwu (que tiene una clase en internet a la que yo me apunté hace unos años).

Finalmente, emplear AWS es una opción excelente desde el punto de vista de coste-eficiencia. Amazon tiene mucha documentación en la red sobre cómo AWS funciona.
Libro de estilo
Uno quiere siempre escribir código que sea:
1. Claro.
2. Robusto.
3. Fácil de mantener.
4. Fácil de compartir.
5. Con menos errores.
Un buen camino para ello es emplear un estilo de escritura consistente y lógico. Hay distintas maneras de conseguir este objetivo y las convenciones a seguir son, en buena medida, materia de gustos. Pero hay que seleccionar un estilo que le venga bien a uno y ser consistente con el mismo a lo largo del tiempo. El secreto es auto-recordarse que lo que es obvio para uno a 21 de Junio de 2017 puede no serlo en dos años cuando el papel llegue de vuelta de la revista con peticiones de cambio. Uno tiene que ser capaz de leer su propio código (o el de sus coautores) en el futuro.
La mayoría de las empresas líderes tienen libros de estilo que uno puede copiar. Por ejemplo, aquí está el de Google para C++ o para Python.

Libros que tratan de estos temas incluyen The Elements of C++ Style de Trevor Misfeldt, Gregory Bumgardner y Andrew Gray y The Elements of MATLAB Style de Richard K. Johnson.
Latex
Como un breve apéndice, y aunque no es estrictamente cuantitativo: uno tiene que aprender Latex. Es la única manera de escribir ecuaciones o de integrar gráficos y tablas con un mínimo de elegancia (o simplemente, sin que Word decida de manera unilateral cambiar de formato).

A pesar de tener muchísimos años, LaTeX: A Document Preparation System (2nd ed.) de Leslie Lamport sigue siendo una introducción magnífica. Mi copia original murió de uso y la segunda no va por mucho mejor camino, aunque la verdad es que ahora suelo mirar en internet más. Libros más avanzados son este y este.
Para escribir en Latex, uno puede emplear un editor normal (como yo en Atom) o uno especializado como TexShop (que empleo para transparencias, porque me resulta más cómodo con Beamer que Atom). Aquí hay una comparativa de los mismos. Overleaf permite escribir Latex de manera colaborativa en la red.
Ahora una pequeña confesión: yo por muchos años no empleé BibTex. Me daba pereza teclear las entradas. En retrospectiva, es de las cosas más bobas que he hecho nunca y he terminado, con los años, malgastando mucho tiempo. Además, hoy, sitios como IDEAS o casi todas las revistas tienen las citas directamente en BibTex y no hace falta nada más que bajárselas. Así que lo mejor es empezar a emplear BibTex desde el día uno.
Conclusión
Ha sido este un largo camino, tanto para mí (escribir cada una de estas entradas es bastante esfuerzo de tiempo, aunque solo sea por organizar las imágenes) como para el lector, que si ha seguido las cinco entradas habrá leído más de 15.000 palabras (18000 si uno incluye la entrada de aprendizaje automático de Diciembre que motivo la serie) y me he dejado muchas cosas sin explicar). Además la información podrá haber abrumado a estudiantes jóvenes que tienen mucho camino que recorrer.
La idea, sin embargo, no es aprenderlo todo de la noche al día. Es ir, pasito a pasito, afianzándose en una serie de competencias que son claves para un investigador moderno. Es increíblemente fácil escribir una columna en el periódico o una entrada en un blog postulando que “A causa B”. Es mucho más difícil sentarse y escribir un modelo lógicamente consistente (las matemáticas nos descubren una y otra vez que mecanismos que parecían obvios en la discusión verbal se caen como una torre de naipes una vez que vemos los efectos de todos los agentes interactuando entre ellos), ponerlo en el ordenador y que las cosas salgan con el efecto cuantitativo que tienen que salir. Los modelos son tozudos y las restricciones impuestas por los datos mucho más. Lo normal es que las 10 primeras cosas que se te ocurran no funcionen como explicación del mundo. Pero de alguna manera ahí está la gracia y para eso sirven los métodos cuantitativos. Como dice Guillermo de Baskerville en El Nombre de la Rosa, si tuviera una única respuesta a mis preguntas, estaría enseñando teología en París y no economía en Penn.